Binomial fordeling av en diskret tilfeldig variabel. Binomialfordeling Genererende funksjon av binomialfordeling
I dette og de neste innleggene skal vi se på matematiske modeller av tilfeldige hendelser. Matematisk modell er et matematisk uttrykk som representerer en tilfeldig variabel. For diskrete tilfeldige variabler er dette matematiske uttrykket kjent som distribusjonsfunksjonen.
Hvis problemet tillater deg å eksplisitt skrive et matematisk uttrykk som representerer en tilfeldig variabel, kan du beregne den nøyaktige sannsynligheten for hvilken som helst av verdiene. I dette tilfellet kan du beregne og liste alle fordelingsfunksjonsverdiene. En rekke fordelinger av tilfeldige variabler oppstår i forretningsmessige, sosiologiske og medisinske applikasjoner. En av de mest nyttige distribusjonene er binomialet.
Binomial fordeling brukes til å simulere situasjoner preget av følgende funksjoner.
- Prøven består av et fast antall elementer n, som representerer resultatene av en bestemt test.
- Hvert prøveelement tilhører en av to gjensidig utelukkende kategorier som tar ut hele prøverommet. Vanligvis kalles disse to kategoriene suksess og fiasko.
- Sannsynlighet for suksess R er konstant. Derfor er sannsynligheten for feil 1 – s.
- Utfallet (dvs. suksess eller fiasko) av en prøveperiode avhenger ikke av utfallet av en annen prøvelse. For å sikre uavhengighet av utfall, innhentes prøveelementer vanligvis ved hjelp av to forskjellige metoder. Hvert prøveelement er tilfeldig trukket fra en uendelig befolkning uten avkastning eller fra en begrenset befolkning med avkastning.
Last ned notatet i eller format, eksempler i format
Binomialfordelingen brukes til å estimere antall suksesser i et utvalg bestående av n observasjoner. La oss ta bestilling som et eksempel. For å legge inn en bestilling kan kunder fra Saxon Company bruke det interaktive elektroniske skjemaet og sende det til selskapet. Informasjonssystemet sjekker deretter for feil, ufullstendige eller uriktige opplysninger i bestillingene. Enhver bestilling er flagget og inkludert i den daglige unntaksrapporten. Data samlet inn av selskapet indikerer at sannsynligheten for feil i bestillinger er 0,1. En bedrift vil gjerne vite hva sannsynligheten er for å finne et visst antall feilbestillinger i et gitt utvalg. Anta for eksempel at kundene fullførte fire elektroniske skjemaer. Hva er sannsynligheten for at alle bestillinger vil være feilfrie? Hvordan beregne denne sannsynligheten? Ved suksess vil vi forstå en feil når du fyller ut skjemaet, og alle andre utfall vil bli ansett som mislykkede. Husk at vi er interessert i antall feilbestillinger i en gitt prøve.
Hvilke utfall kan vi se? Hvis prøven består av fire ordrer, kan én, to, tre eller alle fire være feil, og alle kan være riktige. Kan en tilfeldig variabel som beskriver antall feil utfylte skjemaer få en annen verdi? Dette er ikke mulig fordi antall feilskjemaer ikke kan overstige prøvestørrelsen n eller være negativ. Dermed tar en tilfeldig variabel som følger loven om binomialfordeling verdier fra 0 til n.
La oss anta at i et utvalg av fire ordrer er følgende utfall observert:
Hva er sannsynligheten for å finne tre feilbestillinger i et utvalg på fire bestillinger, i den angitte rekkefølgen? Siden foreløpig forskning har vist at sannsynligheten for en feil ved utfylling av skjemaet er 0,10, beregnes sannsynlighetene for de ovennevnte utfallene som følger:
Siden utfallene ikke er avhengige av hverandre, er sannsynligheten for den angitte utfallsrekkefølgen lik: p*p*(1–p)*p = 0,1*0,1*0,9*0,1 = 0,0009. Hvis du trenger å beregne antall valg X n elementer, bør du bruke kombinasjonsformelen (1):

hvor n! = n * (n –1) * (n – 2) * … * 2 * 1 - faktor for et tall n, og 0! = 1 og 1! = 1 per definisjon.
Dette uttrykket blir ofte referert til som . Således, hvis n = 4 og X = 3, bestemmes antallet sekvenser som består av tre elementer ekstrahert fra en prøvestørrelse på 4 av følgende formel:
Derfor beregnes sannsynligheten for å oppdage tre feilordre som følger:
(Antall mulige sekvenser) *
(sannsynlighet for en bestemt sekvens) = 4 * 0,0009 = 0,0036
På samme måte kan du beregne sannsynligheten for at det blant fire ordrer vil være en eller to feil, samt sannsynligheten for at alle ordre er feil eller alle er korrekte. Imidlertid med økende utvalgsstørrelse nå bestemme sannsynligheten for en bestemt sekvens av utfall blir vanskeligere. I dette tilfellet bør du bruke den passende matematiske modellen som beskriver binomialfordelingen av antall valg X objekter fra et utvalg som inneholder n elementer.
Binomial fordeling

Hvor P(X)- sannsynlighet X suksess for en gitt prøvestørrelse n og sannsynlighet for suksess R, X = 0, 1, … n.
Vær oppmerksom på at formel (2) er en formalisering av intuitive konklusjoner. Tilfeldig verdi X, som adlyder binomialfordelingen, kan ta en hvilken som helst heltallsverdi i området fra 0 til n. Arbeid RX(1 – p)n – X representerer sannsynligheten for at en bestemt sekvens består av X suksess i en prøvestørrelse lik n. Verdien bestemmer antall mulige kombinasjoner som består av X suksess i n tester. Derfor, for et gitt antall tester n og sannsynlighet for suksess R sannsynligheten for en sekvens som består av X suksess, likeverdig
P(X) = (antall mulige sekvenser) * (sannsynlighet for en bestemt sekvens) = 
La oss vurdere eksempler som illustrerer anvendelsen av formel (2).
1. La oss anta at sannsynligheten for å fylle ut skjemaet feil er 0,1. Hva er sannsynligheten for at tre av fire utfylte skjemaer vil være feil? Ved å bruke formel (2) finner vi at sannsynligheten for å oppdage tre feilordre i en prøve bestående av fire ordrer er lik
2. La oss anta at sannsynligheten for å fylle ut skjemaet feil er 0,1. Hva er sannsynligheten for at minst tre av fire utfylte skjemaer vil være feil? Som vist i forrige eksempel, er sannsynligheten for at tre av fire utfylte skjemaer vil være feil 0,0036. For å beregne sannsynligheten for at minst tre vil være feil blant fire utfylte skjemaer, må du legge til sannsynligheten for at blant fire utfylte skjemaer tre vil være feil og sannsynligheten for at alle fire utfylte skjemaer vil være feil. Sannsynligheten for den andre hendelsen er
Dermed er sannsynligheten for at blant fire utfylte skjemaer vil minst tre være feil lik
P(X > 3) = P(X = 3) + P(X = 4) = 0,0036 + 0,0001 = 0,0037
3. La oss anta at sannsynligheten for å fylle ut skjemaet feil er 0,1. Hva er sannsynligheten for at mindre enn tre av fire utfylte skjemaer vil være feil? Sannsynligheten for denne hendelsen
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Ved å bruke formel (2) beregner vi hver av disse sannsynlighetene:

Derfor P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Sannsynlighet P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Deretter P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
Ettersom prøvestørrelsen øker n beregninger som ligner de som ble utført i eksempel 3 blir vanskelige. For å unngå disse komplikasjonene er mange binomiale sannsynligheter tabellert på forhånd. Noen av disse sannsynlighetene er vist i fig. 1. For eksempel for å få sannsynligheten for at X= 2 kl n= 4 og s= 0,1, bør du trekke ut tallet i skjæringspunktet mellom linjen fra tabellen X= 2 og kolonner R = 0,1.

Ris. 1. Binomial sannsynlighet kl n = 4, X= 2 og R = 0,1
Binomialfordelingen kan beregnes ved hjelp av Excel-funksjonen =BINOM.DIST() (fig. 2), som har 4 parametere: antall suksesser - X, antall tester (eller prøvestørrelse) – n, sannsynlighet for suksess – R, parameter integrert, som tar verdien TRUE (i dette tilfellet beregnes sannsynligheten ikke mindre X hendelser) eller FALSE (i dette tilfellet beregnes sannsynligheten nøyaktig X arrangementer).

Ris. 2. Funksjonsparametere =BINOM.DIST()
For de tre eksemplene ovenfor er beregningene vist i fig. 3 (se også Excel-fil). Hver kolonne inneholder én formel. Tallene viser svarene på eksemplene på det tilsvarende tallet).

Ris. 3. Beregning av binomialfordeling i Excel for n= 4 og s = 0,1
Egenskaper til binomialfordelingen
Binomial fordeling avhenger av parametere n Og R. Binomialfordelingen kan enten være symmetrisk eller asymmetrisk. Hvis p = 0,05, er binomialfordelingen symmetrisk uavhengig av parameterens verdi n. Imidlertid, hvis p ≠ 0,05, blir fordelingen skjev. Jo nærmere parameterverdien R til 0,05 og jo større prøvestørrelsen er n, jo mindre uttalt er asymmetrien til fordelingen. Dermed er fordelingen av antall feil utfylte skjema skjev til høyre pga s= 0,1 (fig. 4).

Ris. 4. Histogram over binomialfordeling ved n= 4 og s = 0,1
Forventning til binomialfordeling lik produktet av prøvestørrelsen n på sannsynligheten for suksess R:
(3) M = E(X) =n.p.
I gjennomsnitt, med en tilstrekkelig lang rekke av tester i et utvalg bestående av fire bestillinger, kan det være p = E(X) = 4 x 0,1 = 0,4 feilutfylte skjemaer.
Standardavvik for binomialfordelingen
For eksempel standardavviket for antall feilutfylte skjemaer i et regnskap informasjon System er lik:
Det benyttes materiell fra boken Levin mfl. Statistikk for ledere. – M.: Williams, 2004. – s. 307–313
Ikke alle fenomener måles på en kvantitativ skala som 1, 2, 3... 100500... Et fenomen kan ikke alltid anta et uendelig eller stort antall forskjellige tilstander. For eksempel kan en persons kjønn være enten M eller F. Skytteren treffer enten målet eller bommer. Du kan stemme enten "For" eller "Imot" osv. og så videre. Med andre ord reflekterer slike data tilstanden til et alternativt attributt - enten "ja" (hendelsen skjedde) eller "nei" (hendelsen skjedde ikke). Den inntreffende hendelsen (positivt utfall) kalles også "suksess".
Eksperimenter med slike data kalles Bernoulli-opplegg, til ære for den berømte sveitsiske matematikeren som etablerte at når store mengder tester, forholdet mellom positive utfall og det totale antallet tester har en tendens til sannsynligheten for at denne hendelsen inntreffer.
Alternativ karakteristisk variabel
For å bruke matematiske apparater i analysen bør resultatene av slike observasjoner registreres i numerisk form. For å gjøre dette tildeles et positivt utfall tallet 1, et negativt utfall - 0. Vi har med andre ord å gjøre med en variabel som bare kan ha to verdier: 0 eller 1.
Hvilken fordel kan man få ut av dette? Egentlig ikke mindre enn fra vanlige data. Dermed er det enkelt å beregne antall positive utfall – bare summer opp alle verdiene, dvs. alle 1 (suksess). Du kan gå lenger, men dette vil kreve at du introduserer et par notasjoner.
Det første å merke seg er at positive utfall (som er lik 1) har en viss sannsynlighet for å inntreffe. For eksempel, å få hoder når du kaster en mynt er ½ eller 0,5. Denne sannsynligheten er tradisjonelt betegnet med den latinske bokstaven s. Derfor er sannsynligheten for at en alternativ hendelse inntreffer lik 1 - s, som også er betegnet med q, det er q = 1 – p. Disse notasjonene kan tydelig systematiseres i form av en variabel distribusjonstabell X.
Vi mottok en liste over mulige verdier og deres sannsynligheter. Kan beregnes forventet verdi Og spredning. Forventningen er summen av produktene av alle mulige verdier og deres tilsvarende sannsynligheter:
![]()
La oss beregne forventningen ved å bruke notasjonen i tabellene ovenfor.
Det viser seg at den matematiske forventningen til et alternativt tegn er lik sannsynligheten for denne hendelsen - s.
La oss nå definere hva variansen til et alternativt attributt er. Dispersjon er det gjennomsnittlige kvadratet av avvik fra den matematiske forventningen. Generell formel(for diskrete data) har formen:
Derav variansen til det alternative attributtet:

Det er lett å se at denne spredningen har maksimalt 0,25 (med p=0,5).
Standardavvik er roten til variansen:
Maksimumsverdien overstiger ikke 0,5.
Som du kan se, har både den matematiske forventningen og variansen til det alternative attributtet en veldig kompakt form.
Binomial fordeling av en tilfeldig variabel
La oss se på situasjonen fra en annen vinkel. Faktisk, hvem bryr seg om at det gjennomsnittlige tapet av hoder per kast er 0,5? Det er umulig å forestille seg. Det er mer interessant å stille spørsmålet om antall hoder som oppstår for et gitt antall kast.
Med andre ord er forskeren ofte interessert i sannsynligheten for at et visst antall vellykkede hendelser inntreffer. Dette kan være antall defekte produkter i den testede batchen (1 - defekt, 0 - bra) eller antall gjenopprettinger (1 - frisk, 0 - syk) osv. Antallet slike "suksesser" vil være lik summen av alle verdiene til variabelen X, dvs. antall enkeltutfall.
Tilfeldig verdi B kalles binomial og tar verdier fra 0 til n(på B= 0 – alle deler er egnet, med B = n– alle deler er defekte). Det forutsettes at alle verdier x uavhengige av hverandre. La oss vurdere hovedkarakteristikkene til en binomial variabel, det vil si at vi vil etablere dens matematiske forventning, spredning og distribusjon.
Forventningen til en binomial variabel er veldig lett å oppnå. Den matematiske forventningen til summen av mengder er summen av de matematiske forventningene til hver tilført mengde, og den er lik for alle, derfor:
For eksempel er den matematiske forventningen til antall hoder som faller i 100 kast 100 × 0,5 = 50.
Nå utleder vi formelen for spredningen av en binomial variabel. Variansen av summen av uavhengige tilfeldige variabler er summen av variansene. Herfra
Standardavvik, henholdsvis
For 100 myntkast er standardavviket for antall hoder
Vurder til slutt fordelingen av binomialverdien, dvs. sannsynligheten for at den tilfeldige variabelen B vil få ulike verdier k, Hvor 0≤k≤n. For en mynt kan dette problemet se slik ut: Hva er sannsynligheten for å få 40 hoder på 100 kast?
For å forstå beregningsmetoden, se for deg at mynten bare kastes 4 ganger. Hver side kan falle ut hver gang. Vi spør oss selv: hva er sannsynligheten for å få 2 hoder av 4 kast. Hvert kast er uavhengig av hverandre. Dette betyr at sannsynligheten for å få en hvilken som helst kombinasjon vil være lik produktet av sannsynlighetene for et gitt utfall for hvert enkelt kast. La O være hoder, P være haler. Da kan for eksempel en av kombinasjonene som passer oss se ut som OOPP, det vil si:

Sannsynligheten for en slik kombinasjon er lik produktet av to sannsynligheter for å få hoder og ytterligere to sannsynligheter for å ikke få hoder (den omvendte hendelsen, beregnet som 1 - s), dvs. 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. Dette er sannsynligheten for en av kombinasjonene som passer oss. Men spørsmålet handlet om det totale antallet ørner, og ikke om noen i en bestemt rekkefølge. Deretter må du legge sammen sannsynlighetene for alle kombinasjoner der det er nøyaktig 2 hoder. Det er klart at de alle er like (produktet endres ikke når faktorene endres). Derfor må du beregne antallet og deretter multiplisere med sannsynligheten for en slik kombinasjon. La oss telle alle kombinasjoner av 4 kast med 2 hoder: RROO, RORO, ROOR, ORRO, OROR, OORR. Det er 6 alternativer totalt.

Derfor er den ønskede sannsynligheten for å få 2 hoder etter 4 kast 6×0,0625=0,375.
Det er imidlertid kjedelig å telle på denne måten. Allerede for 10 mynter vil det være svært vanskelig å få det totale antallet alternativer med brute force. Derfor har smarte mennesker for lenge siden funnet opp en formel som de beregner antall forskjellige kombinasjoner av n elementer av k, Hvor n– totalt antall elementer, k– antall elementer hvis arrangementsalternativer telles. Kombinasjonsformel av n elementer av k er dette:
![]()
Lignende ting skjer i kombinatorikkdelen. Jeg sender alle som ønsker å forbedre sine kunnskaper dit. Derav, forresten, navnet på binomialfordelingen (formelen ovenfor er en koeffisient i utvidelsen av Newtons binomiale).
Formelen for å bestemme sannsynlighet kan lett generaliseres til en hvilken som helst mengde n Og k. Som et resultat har formelen for binomialfordelingen følgende form.
Antall kombinasjoner som oppfyller betingelsen multipliseres med sannsynligheten for en av dem.
For praktisk bruk er det nok bare å kjenne formelen til binomialfordelingen. Eller du vet kanskje ikke engang - nedenfor viser vi hvordan du bestemmer sannsynligheten ved å bruke Excel. Men det er bedre å vite.
Ved å bruke denne formelen beregner vi sannsynligheten for å få 40 hoder på 100 kast:
Eller bare 1,08%. Til sammenligning er sannsynligheten for at den matematiske forventningen til dette eksperimentet, det vil si 50 hoder, lik 7,96%. Maksimal sannsynlighet for en binomial verdi tilhører verdien som tilsvarer den matematiske forventningen.
Beregne sannsynligheten for en binomialfordeling i Excel
Hvis du bare bruker papir og en kalkulator, er beregninger ved hjelp av binomialfordelingsformelen, til tross for fravær av integraler, ganske vanskelige. For eksempel er verdien 100! – har mer enn 150 tegn. Tidligere, og selv nå, ble omtrentlige formler brukt for å beregne slike mengder. For øyeblikket er det tilrådelig å bruke spesiell programvare, for eksempel MS Excel. Dermed kan enhver bruker (selv en humanist av opplæring) enkelt beregne sannsynligheten for en binomialt distribuert verdi tilfeldig variabel.
For å konsolidere materialet vil vi foreløpig bruke Excel som en vanlig kalkulator, d.v.s. La oss utføre en trinnvis beregning ved hjelp av binomialfordelingsformelen. La oss beregne for eksempel sannsynligheten for å få 50 hoder. Nedenfor er et bilde med beregningstrinnene og det endelige resultatet.

Som du kan se, er mellomresultatene av en slik skala at de ikke passer inn i cellen, selv om de brukes overalt enkle funksjoner typer: FACTOR (beregning av faktorial), POWER (heve et tall til en potens), samt multiplikasjons- og divisjonsoperatorer. Dessuten er denne beregningen ganske tungvint; i alle fall er den ikke kompakt, fordi mange celler er involvert. Ja, og det er litt vanskelig å finne ut med en gang.
Generelt gir Excel en ferdig funksjon for å beregne sannsynlighetene for en binomialfordeling. Funksjonen kalles BINOM.DIST.

Antall suksesser – antall vellykkede tester. Vi har 50 av dem.
Antall tester – antall kast: 100 ganger.
Sannsynlighet for suksess – Sannsynligheten for å få hoder i ett kast er 0,5.
Integral – angis enten 1 eller 0. Hvis 0, beregnes sannsynligheten P(B=k); hvis 1, vil binomialfordelingsfunksjonen beregnes, dvs. summen av alle sannsynligheter fra B=0 før B=k inklusive.
Klikk OK og få samme resultat som ovenfor, kun alt ble beregnet av en funksjon.

Veldig komfortabelt. For eksperimentets skyld, i stedet for den siste parameteren 0, setter vi 1. Vi får 0,5398. Dette betyr at med 100 myntkast er sannsynligheten for å få hoder mellom 0 og 50 nesten 54%. Men først så det ut til at det burde være 50 %. Generelt gjøres beregninger raskt og enkelt.
En ekte analytiker må forstå hvordan funksjonen oppfører seg (hva er dens fordeling), så vi vil beregne sannsynlighetene for alle verdier fra 0 til 100. Det vil si at vi vil stille spørsmålet: hva er sannsynligheten for at ikke en eneste ørn vil dukke opp, at 1 ørn vil dukke opp, 2, 3, 50, 90 eller 100. Beregningen er vist i følgende bilde. Den blå linjen er selve binomialfordelingen, den røde prikken er sannsynligheten for et spesifikt antall suksesser k.

Man kan spørre seg om binomialfordelingen er lik... Ja, veldig lik. Even Moivre (i 1733) sa at binomialfordelingen med store utvalg nærmer seg (jeg vet ikke hva den het da), men ingen hørte på ham. Bare Gauss, og deretter Laplace 60-70 år senere, ble gjenoppdaget og nøye studert normal lov distribusjoner. Grafen over viser tydelig at den maksimale sannsynligheten faller på den matematiske forventningen, og ettersom den avviker fra den, avtar den kraftig. Akkurat som vanlig lov.
Binomialfordelingen er av stor praktisk betydning og forekommer ganske ofte. Ved hjelp av Excel gjøres beregninger raskt og enkelt.
Binomialfordelingen er en av de viktigste sannsynlighetsfordelingene til en diskret varierende tilfeldig variabel. Binomialfordelingen er sannsynlighetsfordelingen til tallet m forekomst av en hendelse EN V n gjensidig uavhengige observasjoner. Ofte en begivenhet EN kalles "suksess" for en observasjon, og den motsatte hendelsen kalles "feil", men denne betegnelsen er veldig betinget.
Binomiale distribusjonsforhold:
- totalt gjennomført n forsøk der arrangementet EN kan forekomme eller ikke;
- begivenhet EN i hvert forsøk kan forekomme med samme sannsynlighet s;
- tester er gjensidig uavhengige.
Sannsynligheten for at i n testhendelse EN det kommer akkurat m ganger, kan beregnes ved å bruke Bernoullis formel:
![]()
Hvor s- sannsynlighet for at en hendelse inntreffer EN;
q = 1 - s- sannsynligheten for at den motsatte hendelsen inntreffer.
La oss finne ut av det hvorfor er binomialfordelingen relatert til Bernoullis formel på måten beskrevet ovenfor? . Arrangement - antall suksesser kl n tester er delt inn i en rekke alternativer, i hver av dem oppnås suksess i m tester og feil - inn n - m tester. La oss vurdere ett av disse alternativene - B1 . Ved å bruke regelen for å legge til sannsynligheter, multipliserer vi sannsynlighetene for motsatte hendelser:
![]() ,
,
og hvis vi betegner q = 1 - s, Det
![]() .
.
Ethvert annet alternativ der m suksess og n - m feil. Antall slike alternativer er lik antall måter man kan n test få m suksess.
Summen av alle sannsynligheter m hendelsesforekomstnummer EN(tall fra 0 til n) er lik én:
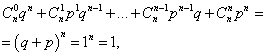
hvor hvert ledd representerer et ledd i Newtons binomiale. Derfor kalles fordelingen under vurdering binomialfordelingen.
I praksis er det ofte nødvendig å regne ut sannsynligheter «ikke mer enn m suksess i n tester" eller "minst m suksess i n tester". Følgende formler brukes til dette.
Integralfunksjonen, altså sannsynlighet F(m) hva er i n observasjonshendelse EN det kommer ikke flere m en gang, kan beregnes ved hjelp av formelen:
I sin tur sannsynlighet F(≥m) hva er i n observasjonshendelse EN kommer ikke mindre m en gang, beregnes med formelen:
Noen ganger er det mer praktisk å beregne sannsynligheten for at n observasjonshendelse EN det kommer ikke flere m ganger, gjennom sannsynligheten for den motsatte hendelsen:
![]() .
.
Hvilken formel du skal bruke avhenger av hvilken av dem som har summen som inneholder færre ledd.
Egenskapene til binomialfordelingen beregnes ved å bruke følgende formler .
Forventet verdi: .
Spredning: .
Standardavvik: .
Binomialfordeling og beregninger i MS Excel
Binomisk sannsynlighet P n ( m) og verdiene til integralfunksjonen F(m) kan beregnes ved hjelp av MS Excel-funksjonen BINOM.DIST. Vinduet for den tilsvarende beregningen vises nedenfor (venstreklikk for å forstørre).

MS Excel krever at du oppgir følgende data:
- antall suksesser;
- antall tester;
- sannsynlighet for suksess;
- integral - logisk verdi: 0 - hvis du trenger å regne ut sannsynligheten P n ( m) og 1 - hvis sannsynligheten F(m).
Eksempel 1. Bedriftslederen oppsummerte informasjon om antall solgte kameraer de siste 100 dagene. Tabellen oppsummerer informasjonen og beregner sannsynlighetene for at et visst antall kameraer vil bli solgt per dag.
Dagen avsluttes med overskudd dersom det selges 13 eller flere kameraer. Sannsynlighet for at dagen vil bli lønnsomt:
![]()
Sannsynlighet for at en dag vil bli jobbet uten fortjeneste:

La sannsynligheten for at en dag jobbes med overskudd være konstant og lik 0,61, og antall solgte kameraer per dag er ikke avhengig av dagen. Da kan vi bruke binomialfordelingen, hvor hendelsen EN- dagen skal jobbes med overskudd, - uten overskudd.
Sannsynlighet for at alle 6 dagene vil bli utført med overskudd:
![]() .
.
Vi får det samme resultatet ved å bruke MS Excel-funksjonen BINOM.DIST (verdien av integralverdien er 0):
P 6 (6 ) = BINOM.FORDELING(6; 6; 0,61; 0) = 0,052.
Sannsynligheten for at 4 eller flere dager av 6 dager vil bli arbeidet med fortjeneste:
Hvor ![]() ,
,
![]() ,
,
Ved å bruke MS Excel-funksjonen BINOM.DIST beregner vi sannsynligheten for at av 6 dager ikke mer enn 3 dager vil bli fullført med overskudd (verdien av integralverdien er 1):
P 6 (≤3 ) = BINOM.FORDELING(3; 6; 0,61; 1) = 0,435.
Sannsynlighet for at alle 6 dager vil bli regnet ut med tap:
![]() ,
,
Vi kan beregne den samme indikatoren ved å bruke MS Excel-funksjonen BINOM.DIST:
P 6 (0 ) = BINOM.FORDELING(0; 6; 0,61; 0) = 0,0035.
Løs problemet selv og se deretter løsningen
Eksempel 2. Det er 2 hvite kuler og 3 svarte kuler i urnen. En ball tas ut av urnen, fargen settes og settes tilbake. Forsøket gjentas 5 ganger. Antall forekomster av hvite kuler er en diskret tilfeldig variabel X, fordelt i henhold til binomialloven. Tegn en fordelingslov for en tilfeldig variabel. Definer modus, matematisk forventning og spredning.
La oss fortsette å løse problemer sammen
Eksempel 3. Fra budtjenesten dro vi til nettstedene n= 5 bud. Hver kurer er sannsynlig s= 0,3, uavhengig av andre, er sent for objektet. Diskret tilfeldig variabel X- antall sene kurerer. Konstruer en distribusjonsserie for denne tilfeldige variabelen. Finn dens matematiske forventning, varians, standardavvik. Finn sannsynligheten for at minst to kurerer kommer for sent til gjenstandene.
Kapittel 7.
Spesifikke lover for distribusjon av tilfeldige variabler
Typer av lover for distribusjon av diskrete tilfeldige variabler
La en diskret tilfeldig variabel ta verdiene X 1 , X 2 , …, x n,…. Sannsynlighetene for disse verdiene kan beregnes ved hjelp av forskjellige formler, for eksempel ved å bruke de grunnleggende teoremene til sannsynlighetsteori, Bernoullis formel eller noen andre formler. For noen av disse formlene har fordelingsloven et eget navn.
De vanligste lovene for distribusjon av en diskret tilfeldig variabel er binomial, geometrisk, hypergeometrisk og Poisson-fordelingslov.
Binomialfordelingslov
La det produseres n uavhengige forsøk, i hver av dem kan hendelsen dukke opp eller ikke EN. Sannsynligheten for at denne hendelsen skal skje i hver enkelt prøve er konstant, avhenger ikke av prøvenummeret og er lik R=R(EN). Derav sannsynligheten for at hendelsen ikke inntreffer EN i hver test er også konstant og lik q=1–R. Tenk på den tilfeldige variabelen X lik antall forekomster av hendelsen EN V n tester. Selvfølgelig er verdiene til denne mengden like
X 1 =0 – hendelse EN V n tester dukket ikke opp;
X 2 =1 – hendelse EN V n dukket opp en gang i prøvelser;
X 3 =2 – hendelse EN V n tester dukket opp to ganger;
…………………………………………………………..
x n +1 = n- begivenhet EN V n alt dukket opp under testene n en gang.
Sannsynlighetene for disse verdiene kan beregnes ved å bruke Bernoulli-formelen (4.1):
Hvor Til=0, 1, 2, …,n .
Binomialfordelingslov X, lik antall suksesser i n Bernoulli tester, med sannsynlighet for suksess R.
Så, en diskret tilfeldig variabel har en binomialfordeling (eller er fordelt i henhold til binomialloven) hvis dens mulige verdier er 0, 1, 2, ..., n, og de tilsvarende sannsynlighetene beregnes ved hjelp av formel (7.1).
Binomialfordelingen avhenger av to parametere R Og n.
Fordelingsserien til en tilfeldig variabel fordelt i henhold til binomialloven har formen:
| X | … | k | … | n | ||
| R | | … | … | |
Eksempel 7.1 . Tre uavhengige skudd skytes mot målet. Sannsynligheten for å treffe hvert skudd er 0,4. Tilfeldig verdi X– antall treff på målet. Konstruer distribusjonsserien.
Løsning. Mulige verdier for en tilfeldig variabel X er X 1 =0; X 2 =1; X 3 =2; X 4 = 3. La oss finne de tilsvarende sannsynlighetene ved å bruke Bernoullis formel. Det er ikke vanskelig å vise at bruken av denne formelen her er fullstendig berettiget. Merk at sannsynligheten for ikke å treffe målet med ett skudd vil være lik 1-0,4=0,6. Vi får

Distribusjonsserien har følgende form:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
Det er lett å verifisere at summen av alle sannsynligheter er lik 1. Selve stokastisk variabel X fordelt etter binomialloven. ■
La oss finne den matematiske forventningen og variansen til en tilfeldig variabel fordelt i henhold til binomialloven.
Ved løsning av eksempel 6.5 ble det vist at den matematiske forventningen til antall forekomster av hendelsen EN V n uavhengige forsøk, hvis sannsynligheten for forekomst EN i hver test er konstant og lik R, er lik n· R
Dette eksemplet brukte en tilfeldig variabel fordelt i henhold til binomialloven. Derfor er løsningen til eksempel 6.5 i hovedsak et bevis på følgende teorem.
Teorem 7.1. Den matematiske forventningen til en diskret tilfeldig variabel fordelt i henhold til binomialloven er lik produktet av antall forsøk og sannsynligheten for "suksess", dvs. M(X)=n· R.
Teorem 7.2. Variansen til en diskret tilfeldig variabel fordelt i henhold til binomialloven er lik produktet av antall forsøk med sannsynligheten for "suksess" og sannsynligheten for "fiasko", dvs. D(X)=nрq.
Asymmetrien og kurtosisen til en tilfeldig variabel fordelt i henhold til binomialloven bestemmes av formlene
Disse formlene kan oppnås ved å bruke konseptet med innledende og sentrale øyeblikk.
Den binomiale distribusjonsloven ligger til grunn for mange virkelige situasjoner. For store verdier n Binomialfordelingen kan tilnærmes ved å bruke andre distribusjoner, spesielt Poisson-fordelingen.
Giftfordeling
La det være n Bernoulli-tester, med antall tester n stor nok. Det ble tidligere vist at i dette tilfellet (hvis dessuten sannsynligheten R arrangementer EN svært liten) for å finne sannsynligheten for at hendelsen ENå dukke opp T En gang i tester kan du bruke Poisson-formelen (4.9). Hvis den tilfeldige variabelen X betyr antall forekomster av hendelsen EN V n Bernoulli tester, da sannsynligheten for at X vil ta verdien k kan beregnes ved hjelp av formelen
 , (7.2)
, (7.2)
Hvor λ = nр.
Giftfordelingsloven kalles fordelingen av en diskret tilfeldig variabel X, for hvilke mulige verdier er ikke-negative heltall, og sannsynlighetene r t disse verdiene er funnet ved hjelp av formel (7.2).
Omfanget λ = nр kalt parameter Poisson-fordelinger.
En tilfeldig variabel fordelt i henhold til Poissons lov kan få et uendelig antall verdier. Siden for denne fordelingen sannsynligheten R Forekomsten av en hendelse i hver rettssak er liten, så denne fordelingen kalles noen ganger loven om sjeldne hendelser.
Fordelingsserien til en tilfeldig variabel fordelt i henhold til Poissons lov har formen
| X | … | T | … | ||||
| R | … | … |
Det er lett å verifisere at summen av sannsynlighetene til den andre raden er lik 1. For å gjøre dette må du huske at funksjonen kan utvides til en Maclaurin-serie, som konvergerer for evt. X. I dette tilfellet har vi
 . (7.3)
. (7.3)
Som nevnt erstatter Poissons lov den binomiale loven i visse begrensende tilfeller. Et eksempel er den tilfeldige variabelen X, hvis verdier er lik antall feil over en viss tidsperiode under gjentatt bruk av en teknisk enhet. Det antas at dette er en svært pålitelig enhet, dvs. Sannsynligheten for feil i en applikasjon er svært liten.
I tillegg til slike begrensende tilfeller er det i praksis tilfeldige variabler fordelt etter Poissons lov som ikke er assosiert med binomialfordelingen. For eksempel brukes Poisson-fordelingen ofte når det gjelder antall hendelser som skjer i løpet av en tidsperiode (antall anrop mottatt på en telefonsentral i løpet av en time, antall biler som ankommer en bilvask i løpet av en dag, antall maskinstopp per uke osv.). Alle disse hendelsene skal danne den såkalte strømmen av hendelser, som er et av de grunnleggende begrepene i køteori. Parameter λ karakteriserer den gjennomsnittlige intensiteten av strømmen av hendelser.
Eksempel 7.2 . Det er 500 studenter ved fakultetet. Hva er sannsynligheten for at 1. september er bursdagen til tre studenter på denne avdelingen?
Løsning . Siden antall studenter n=500 er ganske stor og R– sannsynligheten for å bli født den første september for noen av elevene er lik , dvs. er liten nok, så kan vi anta at den tilfeldige variabelen X– antall elever født 1. september er fordelt i henhold til Poissons lov med parameteren λ = n.p.= = 1,36986. Da får vi i henhold til formel (7.2).
Teorem 7.3. La den tilfeldige variabelen X distribuert i henhold til Poissons lov. Da er dens matematiske forventning og varians lik hverandre og lik verdien av parameteren λ , dvs. M(X) = D(X) = λ = n.p..
Bevis. Ved definisjon av matematisk forventning, ved å bruke formel (7.3) og fordelingsserien til en tilfeldig variabel fordelt i henhold til Poissons lov, får vi
Før vi finner variansen, finner vi først den matematiske forventningen til kvadratet til den tilfeldige variabelen som vurderes. Vi får

Herfra, per definisjon av spredning, får vi
Teoremet er bevist.
Ved å bruke begrepene initiale og sentrale momenter kan det vises at for en tilfeldig variabel fordelt i henhold til Poissons lov, bestemmes skjevhet og kurtose-koeffisienter av formlene
Det er ikke vanskelig å forstå det, siden det semantiske innholdet i parameteren λ = n.p. er positiv, så har en tilfeldig variabel fordelt i henhold til Poissons lov alltid positiv skjevhet og kurtose.
- (binomial fordeling) En fordeling som lar deg beregne sannsynligheten for forekomsten av enhver tilfeldig hendelse oppnådd som et resultat av observasjoner av en rekke uavhengige hendelser, hvis sannsynligheten for forekomst av dens elementære komponenter ... ... Økonomisk ordbok
- (Bernoulli-fordeling) sannsynlighetsfordeling av antall forekomster av en bestemt hendelse under gjentatte uavhengige forsøk, hvis sannsynligheten for at denne hendelsen inntreffer i hvert forsøk er lik p(0 p 1). Nøyaktig, antallet? forekomster av denne hendelsen er... ... Stor encyklopedisk ordbok
binomial fordeling- - Telekommunikasjonsemner, grunnleggende konsepter EN binomialfordeling ...
- (Bernoulli-fordeling), sannsynlighetsfordelingen av antall forekomster av en bestemt hendelse under gjentatte uavhengige forsøk, hvis sannsynligheten for forekomsten av denne hendelsen i hvert forsøk er lik p (0≤p≤1). Nemlig antallet μ av forekomster av denne hendelsen... ... encyklopedisk ordbok
binomial fordeling- 1,49. binomialfordeling Sannsynlighetsfordeling av en diskret tilfeldig variabel X, som tar alle heltallsverdier fra 0 til n, slik at for x = 0, 1, 2, ..., n og parametere n = 1, 2, ... og 0< p < 1, где Источник … Ordbok-referansebok med vilkår for normativ og teknisk dokumentasjon
Bernoulli-fordeling, sannsynlighetsfordelingen til en tilfeldig variabel X, tar henholdsvis heltallsverdier med sannsynligheter (binomial koeffisient; p-parameteren til B. r., kalt sannsynligheten for et positivt utfall, tar verdiene ... Matematisk leksikon
Sannsynlighetsfordeling av antall forekomster av en bestemt hendelse under gjentatte uavhengige forsøk. Hvis sannsynligheten for at en hendelse skal inntreffe under hvert forsøk er lik p, med 0 ≤ p ≤ 1, så er antallet μ av forekomster av denne hendelsen for n uavhengige... ... Stor Sovjetisk leksikon
- (Bernoulli-fordeling), sannsynlighetsfordelingen av antall forekomster av en bestemt hendelse under gjentatte uavhengige forsøk, hvis sannsynligheten for forekomsten av denne hendelsen i hvert forsøk er lik p (0<или = p < или = 1). Именно, число м появлений … Naturvitenskap. encyklopedisk ordbok
Binomial sannsynlighetsfordeling- (binomial fordeling) En fordeling som observeres i tilfeller der utfallet av hvert uavhengig eksperiment (statistisk observasjon) tar en av to mulige verdier: seier eller nederlag, inkludering eller ekskludering, pluss eller ... Økonomisk og matematisk ordbok
binomisk sannsynlighetsfordeling- En fordeling som observeres i tilfeller der utfallet av hvert uavhengig eksperiment (statistisk observasjon) tar en av to mulige verdier: seier eller nederlag, inkludering eller eksklusjon, pluss eller minus, 0 eller 1. Det vil si... ... Teknisk oversetterveiledning
Bøker
- Sannsynlighetsteori og matematisk statistikk i problemer. Mer enn 360 problemer og øvelser, D. A. Borzykh. Den foreslåtte håndboken inneholder oppgaver av varierende kompleksitetsnivå. Hovedvekten er imidlertid lagt på oppgaver med middels kompleksitet. Dette gjøres med hensikt for å oppmuntre studenter til å...
- Sannsynlighetsteori og matematisk statistikk i problemer Mer enn 360 oppgaver og øvelser, D. Borzykh Den foreslåtte manualen inneholder problemer med varierende kompleksitetsnivå. Hovedvekten er imidlertid lagt på oppgaver med middels kompleksitet. Dette gjøres med hensikt for å oppmuntre studenter til å...
 Russiske studenter vant ICPC World Programming Championship
Russiske studenter vant ICPC World Programming Championship "Denisovan-mannen" "arvet" mest av alt i genomet til asiater
"Denisovan-mannen" "arvet" mest av alt i genomet til asiater Handling for å skremme sjekkpunkter i Chelyabinsk Hva er konseptet offentlig sikkerhet
Handling for å skremme sjekkpunkter i Chelyabinsk Hva er konseptet offentlig sikkerhet