Binomial distribution of a discrete random variable. Binomial distribution Generating function of binomial distribution
In this and the next few posts we will look at mathematical models of random events. Mathematical model is a mathematical expression representing a random variable. For discrete random variables, this mathematical expression is known as the distribution function.
If the problem allows you to explicitly write a mathematical expression representing a random variable, you can calculate the exact probability of any of its values. In this case, you can calculate and list all the distribution function values. A variety of distributions of random variables are encountered in business, sociological, and medical applications. One of the most useful distributions is the binomial.
Binomial distribution used to simulate situations characterized by the following features.
- The sample consists of a fixed number of elements n, representing the outcomes of a certain test.
- Each sample element belongs to one of two mutually exclusive categories that exhaust the entire sample space. Typically these two categories are called success and failure.
- Probability of success R is constant. Therefore, the probability of failure is 1 – p.
- The outcome (i.e. success or failure) of any trial does not depend on the outcome of another trial. To ensure independence of outcomes, sample elements are typically obtained using two different methods. Each sample element is randomly drawn from an infinite population without return or from a finite population with return.
Download the note in or format, examples in format
The binomial distribution is used to estimate the number of successes in a sample consisting of n observations. Let's take ordering as an example. To place an order, Saxon Company customers can use the interactive electronic form and send it to the company. The information system then checks for errors, incomplete or incorrect information in the orders. Any order in question is flagged and included in the daily exception report. Data collected by the company indicates that the probability of errors in orders is 0.1. A company would like to know what the probability is of finding a certain number of erroneous orders in a given sample. For example, suppose customers completed four electronic forms. What is the probability that all orders will be error-free? How to calculate this probability? By success we will understand an error when filling out the form, and all other outcomes will be considered failure. Recall that we are interested in the number of erroneous orders in a given sample.
What outcomes can we see? If the sample consists of four orders, one, two, three, or all four may be incorrect, and all of them may be correct. Can a random variable describing the number of incorrectly completed forms take on any other value? This is not possible because the number of incorrect forms cannot exceed the sample size n or be negative. Thus, a random variable that obeys the binomial distribution law takes values from 0 to n.
Let us assume that in a sample of four orders the following outcomes are observed:
What is the probability of finding three erroneous orders in a sample of four orders, in the specified order? Since preliminary research has shown that the probability of an error when filling out the form is 0.10, the probabilities of the above outcomes are calculated as follows:
Since the outcomes do not depend on each other, the probability of the specified sequence of outcomes is equal to: p*p*(1–p)*p = 0.1*0.1*0.9*0.1 = 0.0009. If you need to calculate the number of choices X n elements, you should use the combination formula (1):

where n! = n * (n –1) * (n – 2) * … * 2 * 1 - factorial of a number n, and 0! = 1 and 1! = 1 by definition.
This expression is often referred to as . Thus, if n = 4 and X = 3, the number of sequences consisting of three elements extracted from a sample size of 4 is determined by the following formula:
Therefore, the probability of detecting three erroneous orders is calculated as follows:
(Number of possible sequences) *
(probability of a particular sequence) = 4 * 0.0009 = 0.0036
Similarly, you can calculate the probability that among four orders there will be one or two erroneous, as well as the probability that all orders are erroneous or all are correct. However, with increasing sample size n determining the probability of a particular sequence of outcomes becomes more difficult. In this case, you should apply the appropriate mathematical model that describes the binomial distribution of the number of choices X objects from a selection containing n elements.
Binomial distribution

Where P(X)- probability X success for a given sample size n and probability of success R, X = 0, 1, … n.
Please note that formula (2) is a formalization of intuitive conclusions. Random value X, which obeys the binomial distribution, can take any integer value in the range from 0 to n. Work RX(1 – p)n – X represents the probability of a particular sequence consisting of X success in a sample size equal to n. The value determines the number of possible combinations consisting of X success in n tests. Therefore, for a given number of tests n and probability of success R probability of a sequence consisting of X success, equal
P(X) = (number of possible sequences) * (probability of a particular sequence) = 
Let us consider examples illustrating the application of formula (2).
1. Let's assume that the probability of filling out the form incorrectly is 0.1. What is the probability that among four completed forms, three will be incorrect? Using formula (2), we find that the probability of detecting three erroneous orders in a sample consisting of four orders is equal to
2. Let's assume that the probability of filling out the form incorrectly is 0.1. What is the probability that among four completed forms, at least three will be incorrect? As shown in the previous example, the probability that among four completed forms, three will be incorrect is 0.0036. To calculate the probability that among four completed forms at least three will be incorrect, you need to add the probability that among four completed forms three will be incorrect and the probability that among four completed forms all will be incorrect. The probability of the second event is
Thus, the probability that among four completed forms at least three will be incorrect is equal to
P(X > 3) = P(X = 3) + P(X = 4) = 0.0036 + 0.0001 = 0.0037
3. Let's assume that the probability of filling out the form incorrectly is 0.1. What is the probability that out of four completed forms, less than three will be incorrect? Probability of this event
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Using formula (2), we calculate each of these probabilities:

Therefore, P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Probability P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Then P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
As the sample size increases n calculations similar to those carried out in example 3 become difficult. To avoid these complications, many binomial probabilities are tabulated in advance. Some of these probabilities are shown in Fig. 1. For example, to get the probability that X= 2 at n= 4 and p= 0.1, you should extract from the table the number at the intersection of the line X= 2 and columns R = 0,1.

Rice. 1. Binomial probability at n = 4, X= 2 and R = 0,1
The binomial distribution can be calculated using the Excel function =BINOM.DIST() (Fig. 2), which has 4 parameters: number of successes - X, number of tests (or sample size) – n, probability of success – R, parameter integral, which takes the value TRUE (in this case, the probability is calculated no less X events) or FALSE (in this case the probability is calculated exactly X events).

Rice. 2. Function parameters =BINOM.DIST()
For the above three examples, the calculations are shown in Fig. 3 (see also Excel file). Each column contains one formula. The numbers show the answers to the examples of the corresponding number).

Rice. 3. Calculation of binomial distribution in Excel for n= 4 and p = 0,1
Properties of the binomial distribution
Binomial distribution depends on parameters n And R. The binomial distribution can be either symmetric or asymmetric. If p = 0.05, the binomial distribution is symmetric regardless of the value of the parameter n. However, if p ≠ 0.05, the distribution becomes skewed. The closer the parameter value R to 0.05 and the larger the sample size n, the less pronounced the asymmetry of the distribution. Thus, the distribution of the number of incorrectly completed forms is skewed to the right because p= 0.1 (Fig. 4).

Rice. 4. Histogram of binomial distribution at n= 4 and p = 0,1
Expectation of binomial distribution equal to the product of the sample size n on the probability of success R:
(3) M = E(X) =n.p.
On average, with a sufficiently long series of tests in a sample consisting of four orders, there may be p = E(X) = 4 x 0.1 = 0.4 incorrectly completed forms.
Standard deviation of the binomial distribution
For example, the standard deviation of the number of incorrectly completed forms in an accounting information system equals:
Materials from the book Levin et al. Statistics for Managers are used. – M.: Williams, 2004. – p. 307–313
Not all phenomena are measured on a quantitative scale such as 1, 2, 3... 100500... A phenomenon cannot always take on an infinite or large number of different states. For example, a person's gender can be either M or F. The shooter either hits the target or misses. You can vote either “For” or “Against”, etc. and so on. In other words, such data reflect the state of an alternative attribute - either “yes” (the event occurred) or “no” (the event did not occur). The occurring event (positive outcome) is also called “success”.
Experiments with such data are called Bernoulli scheme, in honor of the famous Swiss mathematician who established that when large quantities tests, the ratio of positive outcomes and the total number of tests tends to the probability of the occurrence of this event.
Alternative characteristic variable
In order to use mathematical apparatus in the analysis, the results of such observations should be recorded in numerical form. To do this, a positive outcome is assigned the number 1, a negative outcome - 0. In other words, we are dealing with a variable that can only take two values: 0 or 1.
What benefit can be derived from this? Actually, no less than from ordinary data. Thus, it is easy to calculate the number of positive outcomes - just sum up all the values, i.e. all 1 (success). You can go further, but this will require you to introduce a couple of notations.
The first thing to note is that positive outcomes (which are equal to 1) have some probability of occurring. For example, getting heads when tossing a coin is ½ or 0.5. This probability is traditionally denoted by the Latin letter p. Therefore, the probability of an alternative event occurring is equal to 1 - p, which is also denoted by q, that is q = 1 – p. These notations can be clearly systematized in the form of a variable distribution table X.
We received a list of possible values and their probabilities. Can be calculated expected value And dispersion. The expectation is the sum of the products of all possible values and their corresponding probabilities:
![]()
Let's calculate the expectation using the notation in the tables above.
It turns out that the mathematical expectation of an alternative sign is equal to the probability of this event - p.
Now let’s define what the variance of an alternative attribute is. Dispersion is the average square of deviations from the mathematical expectation. General formula(for discrete data) has the form:
Hence the variance of the alternative attribute:

It is easy to see that this dispersion has a maximum of 0.25 (with p=0.5).
Standard deviation is the root of the variance:
The maximum value does not exceed 0.5.
As you can see, both the mathematical expectation and the variance of the alternative attribute have a very compact form.
Binomial distribution of a random variable
Let's look at the situation from a different angle. Indeed, who cares that the average loss of heads per toss is 0.5? It's impossible to even imagine. It is more interesting to ask the question about the number of heads that occur for a given number of throws.
In other words, the researcher is often interested in the probability of a certain number of successful events occurring. This may be the number of defective products in the tested batch (1 - defective, 0 - good) or the number of recoveries (1 - healthy, 0 - sick), etc. The number of such “successes” will be equal to the sum of all values of the variable X, i.e. number of single outcomes.
Random value B is called binomial and takes values from 0 to n(at B= 0 – all parts are suitable, with B = n– all parts are defective). It is assumed that all values x independent from each other. Let's consider the main characteristics of a binomial variable, that is, we will establish its mathematical expectation, dispersion and distribution.
The expectation of a binomial variable is very easy to obtain. The mathematical expectation of the sum of quantities is the sum of the mathematical expectations of each added quantity, and it is the same for everyone, therefore:
For example, the mathematical expectation of the number of heads dropped in 100 tosses is 100 × 0.5 = 50.
Now we derive the formula for the dispersion of a binomial variable. The variance of the sum of independent random variables is the sum of the variances. From here
Standard deviation, respectively
For 100 coin tosses, the standard deviation of the number of heads is
Finally, consider the distribution of the binomial value, i.e. the probability that the random variable B will take on different values k, Where 0≤k≤n. For a coin, this problem might look like this: What is the probability of getting 40 heads on 100 tosses?
To understand the calculation method, imagine that the coin is tossed only 4 times. Either side can fall out every time. We ask ourselves: what is the probability of getting 2 heads out of 4 tosses. Each throw is independent of each other. This means that the probability of getting any combination will be equal to the product of the probabilities of a given outcome for each individual throw. Let O be heads, P be tails. Then, for example, one of the combinations that suits us may look like OOPP, that is:

The probability of such a combination is equal to the product of two probabilities of getting heads and two more probabilities of not getting heads (the reverse event, calculated as 1 - p), i.e. 0.5×0.5×(1-0.5)×(1-0.5)=0.0625. This is the probability of one of the combinations that suits us. But the question was about the total number of eagles, and not about some in a certain order. Then you need to add up the probabilities of all combinations in which there are exactly 2 heads. Clearly, they are all the same (the product does not change when the factors are changed). Therefore, you need to calculate their number and then multiply by the probability of any such combination. Let's count all combinations of 4 throws of 2 heads: RROO, RORO, ROOR, ORRO, OROR, OORR. There are 6 options in total.

Therefore, the desired probability of getting 2 heads after 4 throws is 6×0.0625=0.375.
However, counting this way is tedious. Already for 10 coins, it will be very difficult to obtain the total number of options by brute force. Therefore, smart people long ago invented a formula with which they calculate the number of different combinations of n elements by k, Where n– total number of elements, k– the number of elements, the arrangement options of which are counted. Combination formula of n elements by k is this:
![]()
Similar things happen in the combinatorics section. I send anyone who wants to improve their knowledge there. Hence, by the way, the name of the binomial distribution (the formula above is a coefficient in the expansion of Newton’s binomial).
The formula for determining probability can be easily generalized to any quantity n And k. As a result, the formula for the binomial distribution has the following form.
The number of combinations that meet the condition is multiplied by the probability of one of them.
For practical use, it is enough just to know the formula of the binomial distribution. Or you may not even know - below we show how to determine the probability using Excel. But it’s better to know.
Using this formula, we calculate the probability of getting 40 heads in 100 throws:
Or just 1.08%. For comparison, the probability of the mathematical expectation of this experiment, that is, 50 heads, being equal to 7.96%. The maximum probability of a binomial value belongs to the value corresponding to the mathematical expectation.
Calculating the probability of a binomial distribution in Excel
If you use only paper and a calculator, then calculations using the binomial distribution formula, despite the absence of integrals, are quite difficult. For example, the value is 100! – has more than 150 characters. Previously, and even now, approximate formulas were used to calculate such quantities. At the moment, it is advisable to use special software, such as MS Excel. Thus, any user (even a humanist by training) can easily calculate the probability of a binomially distributed value random variable.
To consolidate the material, we will use Excel for now as a regular calculator, i.e. Let's carry out a step-by-step calculation using the binomial distribution formula. Let's calculate, for example, the probability of getting 50 heads. Below is a picture with the calculation steps and the final result.

As you can see, the intermediate results are of such a scale that they do not fit into the cell, although they are used everywhere simple functions types: FACTOR (calculation of factorial), POWER (raising a number to a power), as well as multiplication and division operators. Moreover, this calculation is quite cumbersome; in any case, it is not compact, because many cells are involved. Yes, and it’s a little difficult to figure out right away.
In general, Excel provides a ready-made function for calculating the probabilities of a binomial distribution. The function is called BINOM.DIST.

Number of successes – number of successful tests. We have 50 of them.
Number of tests – number of throws: 100 times.
Probability of success – the probability of getting heads in one toss is 0.5.
Integral – either 1 or 0 is indicated. If 0, then the probability is calculated P(B=k); if 1, then the binomial distribution function will be calculated, i.e. the sum of all probabilities from B=0 before B=k inclusive.
Click OK and get the same result as above, only everything was calculated by one function.

Very comfortably. For the sake of experimentation, instead of the last parameter 0, we put 1. We get 0.5398. This means that with 100 coin tosses, the probability of getting heads between 0 and 50 is almost 54%. But at first it seemed that it should be 50%. In general, calculations are made quickly and easily.
A real analyst must understand how the function behaves (what is its distribution), so we will calculate the probabilities for all values from 0 to 100. That is, we will ask the question: what is the probability that not a single head will appear, that 1 eagle will appear, 2, 3 , 50, 90 or 100. The calculation is shown in the following picture. The blue line is the binomial distribution itself, the red dot is the probability for a specific number of successes k.

One might ask if the binomial distribution is similar to... Yes, very similar. Even Moivre (in 1733) said that the binomial distribution with large samples approaches (I don’t know what it was called then), but no one listened to him. Only Gauss, and then Laplace 60-70 years later, were rediscovered and carefully studied normal law distributions. The graph above clearly shows that the maximum probability falls on the mathematical expectation, and as it deviates from it, it decreases sharply. Just like the normal law.
The binomial distribution is of great practical importance and occurs quite often. Using Excel, calculations are made quickly and easily.
The binomial distribution is one of the most important probability distributions of a discretely varying random variable. The binomial distribution is the probability distribution of the number m occurrence of an event A V n mutually independent observations. Often an event A is called the “success” of an observation, and the opposite event is called “failure,” but this designation is very conditional.
Binomial distribution conditions:
- in total carried out n trials in which the event A may or may not occur;
- event A in each trial can occur with the same probability p;
- tests are mutually independent.
The probability that in n testing event A it will come exactly m times, can be calculated using Bernoulli's formula:
![]()
Where p- probability of an event occurring A;
q = 1 - p- the probability of the opposite event occurring.
Let's figure it out why is the binomial distribution related to Bernoulli's formula in the manner described above? . Event - number of successes at n tests are divided into a number of options, in each of which success is achieved in m tests, and failure - in n - m tests. Let's consider one of these options - B1 . Using the rule for adding probabilities, we multiply the probabilities of opposite events:
![]() ,
,
and if we denote q = 1 - p, That
![]() .
.
Any other option in which m success and n - m failures. The number of such options is equal to the number of ways in which one can n test get m success.
Sum of all probabilities m event occurrence numbers A(numbers from 0 to n) is equal to one:
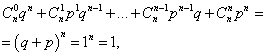
where each term represents a term in Newton's binomial. Therefore, the distribution under consideration is called the binomial distribution.
In practice, it is often necessary to calculate probabilities "no more than m success in n tests" or "at least m success in n tests". The following formulas are used for this.
The integral function, that is probability F(m) what's in n observational event A no more will come m once, can be calculated using the formula:
In its turn probability F(≥m) what's in n observational event A will come no less m once, is calculated by the formula:
Sometimes it is more convenient to calculate the probability that n observational event A no more will come m times, through the probability of the opposite event:
![]() .
.
Which formula to use depends on which of them has the sum containing fewer terms.
The characteristics of the binomial distribution are calculated using the following formulas .
Expected value: .
Dispersion: .
Standard deviation: .
Binomial distribution and calculations in MS Excel
Binomial probability P n( m) and the values of the integral function F(m) can be calculated using the MS Excel function BINOM.DIST. The window for the corresponding calculation is shown below (left click to enlarge).

MS Excel requires you to enter the following data:
- number of successes;
- number of tests;
- probability of success;
- integral - logical value: 0 - if you need to calculate the probability P n( m) and 1 - if the probability F(m).
Example 1. The company manager summarized information on the number of cameras sold over the last 100 days. The table summarizes the information and calculates the probabilities that a certain number of cameras will be sold per day.
The day ends with a profit if 13 or more cameras are sold. Probability that the day will be worked out profitably:
![]()
Probability that a day will be worked without profit:

Let the probability that a day is worked with a profit be constant and equal to 0.61, and the number of cameras sold per day does not depend on the day. Then we can use the binomial distribution, where the event A- the day will be worked with profit, - without profit.
Probability that all 6 days will be worked out with profit:
![]() .
.
We get the same result using the MS Excel function BINOM.DIST (the value of the integral value is 0):
P 6 (6 ) = BINOM.DIST(6; 6; 0.61; 0) = 0.052.
The probability that out of 6 days 4 or more days will be worked with profit:
Where ![]() ,
,
![]() ,
,
Using the MS Excel function BINOM.DIST, we calculate the probability that out of 6 days no more than 3 days will be completed with a profit (the value of the integral value is 1):
P 6 (≤3 ) = BINOM.DIST(3; 6; 0.61; 1) = 0.435.
Probability that all 6 days will be worked out with losses:
![]() ,
,
We can calculate the same indicator using the MS Excel function BINOM.DIST:
P 6 (0 ) = BINOM.DIST(0; 6; 0.61; 0) = 0.0035.
Solve the problem yourself and then see the solution
Example 2. There are 2 white balls and 3 black balls in the urn. A ball is taken out of the urn, the color is set and put back. The attempt is repeated 5 times. The number of occurrences of white balls is a discrete random variable X, distributed according to the binomial law. Draw up a law of distribution of a random variable. Define mode, mathematical expectation and dispersion.
Let's continue to solve problems together
Example 3. From the courier service we went to the sites n= 5 couriers. Each courier is likely p= 0.3, regardless of others, is late for the object. Discrete random variable X- number of late couriers. Construct a distribution series for this random variable. Find its mathematical expectation, variance, standard deviation. Find the probability that at least two couriers will be late for the objects.
Chapter 7.
Specific laws of distribution of random variables
Types of laws of distribution of discrete random variables
Let a discrete random variable take the values X 1 , X 2 , …, x n,…. The probabilities of these values can be calculated using various formulas, for example, using the basic theorems of probability theory, Bernoulli's formula, or some other formulas. For some of these formulas, the distribution law has its own name.
The most common laws of distribution of a discrete random variable are binomial, geometric, hypergeometric, and Poisson distribution law.
Binomial distribution law
Let it be produced n independent trials, in each of which the event may or may not appear A. The probability of this event occurring in each single trial is constant, does not depend on the trial number and is equal to R=R(A). Hence the probability of the event not occurring A in each test is also constant and equal q=1–R. Consider the random variable X equal to the number of occurrences of the event A V n tests. Obviously, the values of this quantity are equal
X 1 =0 – event A V n tests did not appear;
X 2 =1 – event A V n appeared once in trials;
X 3 =2 – event A V n tests appeared twice;
…………………………………………………………..
x n +1 = n- event A V n everything appeared during the tests n once.
The probabilities of these values can be calculated using the Bernoulli formula (4.1):
Where To=0, 1, 2, …,n .
Binomial distribution law X, equal to the number of successes in n Bernoulli tests, with probability of success R.
So, a discrete random variable has a binomial distribution (or is distributed according to the binomial law) if its possible values are 0, 1, 2, ..., n, and the corresponding probabilities are calculated using formula (7.1).
The binomial distribution depends on two parameters R And n.
The distribution series of a random variable distributed according to the binomial law has the form:
| X | … | k | … | n | ||
| R | | … | … | |
Example 7.1 . Three independent shots are fired at the target. The probability of hitting each shot is 0.4. Random value X– number of hits on the target. Construct its distribution series.
Solution. Possible values of a random variable X are X 1 =0; X 2 =1; X 3 =2; X 4 =3. Let's find the corresponding probabilities using Bernoulli's formula. It is not difficult to show that the use of this formula here is completely justified. Note that the probability of not hitting the target with one shot will be equal to 1-0.4=0.6. We get

The distribution series has the following form:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
It is easy to verify that the sum of all probabilities is equal to 1. The random variable itself X distributed according to the binomial law. ■
Let's find the mathematical expectation and variance of a random variable distributed according to the binomial law.
When solving Example 6.5, it was shown that the mathematical expectation of the number of occurrences of the event A V n independent trials, if the likelihood of occurrence A in each test is constant and equal R, equals n· R
This example used a random variable distributed according to the binomial law. Therefore, the solution to Example 6.5 is essentially a proof of the following theorem.
Theorem 7.1. The mathematical expectation of a discrete random variable distributed according to the binomial law is equal to the product of the number of trials and the probability of “success”, i.e. M(X)=n· R.
Theorem 7.2. The variance of a discrete random variable distributed according to the binomial law is equal to the product of the number of trials by the probability of “success” and the probability of “failure”, i.e. D(X)=nрq.
The asymmetry and kurtosis of a random variable distributed according to the binomial law are determined by the formulas
These formulas can be obtained using the concept of initial and central moments.
The binomial distribution law underlies many real-life situations. For large values n The binomial distribution can be approximated using other distributions, in particular the Poisson distribution.
Poisson distribution
Let there be n Bernoulli tests, with the number of tests n big enough. It was shown earlier that in this case (if, moreover, the probability R events A very small) to find the probability that the event A to appear T Once in tests, you can use the Poisson formula (4.9). If the random variable X means the number of occurrences of the event A V n Bernoulli tests, then the probability that X will take the value k can be calculated using the formula
 , (7.2)
, (7.2)
Where λ = nр.
Poisson distribution law is called the distribution of a discrete random variable X, for which possible values are non-negative integers, and the probabilities r t these values are found using formula (7.2).
Magnitude λ = nр called parameter Poisson distributions.
A random variable distributed according to Poisson's law can take on an infinite number of values. Since for this distribution the probability R The occurrence of an event in each trial is small, then this distribution is sometimes called the law of rare events.
The distribution series of a random variable distributed according to Poisson's law has the form
| X | … | T | … | ||||
| R | … | … |
It is easy to verify that the sum of the probabilities of the second row is equal to 1. To do this, you need to remember that the function can be expanded into a Maclaurin series, which converges for any X. In this case we have
 . (7.3)
. (7.3)
As noted, Poisson's law replaces the binomial law in certain limiting cases. An example is the random variable X, the values of which are equal to the number of failures over a certain period of time during repeated use of a technical device. It is assumed that this is a highly reliable device, i.e. The probability of failure in one application is very small.
In addition to such limiting cases, in practice there are random variables distributed according to Poisson's law that are not associated with the binomial distribution. For example, the Poisson distribution is often used when dealing with the number of events occurring in a period of time (the number of calls received at a telephone exchange during an hour, the number of cars arriving at a car wash during a day, the number of machine stops per week, etc. .). All these events should form the so-called flow of events, which is one of the basic concepts of queuing theory. Parameter λ characterizes the average intensity of the flow of events.
Example 7.2 . There are 500 students at the faculty. What is the probability that September 1st is the birthday of three students in this department?
Solution . Since the number of students n=500 is quite large and R– the probability of being born on the first of September for any of the students is equal to , i.e. is small enough, then we can assume that the random variable X– the number of students born on September 1st is distributed according to Poisson’s law with the parameter λ = n.p.= =1.36986. Then, according to formula (7.2) we get
Theorem 7.3. Let the random variable X distributed according to Poisson's law. Then its mathematical expectation and variance are equal to each other and equal to the value of the parameter λ , i.e. M(X) = D(X) = λ = n.p..
Proof. By definition of mathematical expectation, using formula (7.3) and the distribution series of a random variable distributed according to Poisson’s law, we obtain
Before finding the variance, we first find the mathematical expectation of the square of the random variable under consideration. We get

From here, by definition of dispersion, we get
The theorem has been proven.
Using the concepts of initial and central moments, it can be shown that for a random variable distributed according to Poisson’s law, the skewness and kurtosis coefficients are determined by the formulas
It is not difficult to understand that, since the semantic content of the parameter λ = n.p. is positive, then a random variable distributed according to Poisson’s law always has positive skewness and kurtosis.
- (binomial distribution) A distribution that allows you to calculate the probability of the occurrence of any random event obtained as a result of observations of a number of independent events, if the probability of occurrence of its elementary components ... ... Economic dictionary
- (Bernoulli distribution) probability distribution of the number of occurrences of a certain event during repeated independent trials, if the probability of the occurrence of this event in each trial is equal to p(0 p 1). Exactly, the number? occurrences of this event are... ... Big Encyclopedic Dictionary
binomial distribution- - Telecommunications topics, basic concepts EN binomial distribution ...
- (Bernoulli distribution), the probability distribution of the number of occurrences of a certain event during repeated independent trials, if the probability of the occurrence of this event in each trial is equal to p (0≤p≤1). Namely, the number μ of occurrences of this event... ... encyclopedic Dictionary
binomial distribution- 1.49. binomial distribution Probability distribution of a discrete random variable X, taking any integer values from 0 to n, such that for x = 0, 1, 2, ..., n and parameters n = 1, 2, ... and 0< p < 1, где Источник … Dictionary-reference book of terms of normative and technical documentation
Bernoulli distribution, the probability distribution of a random variable X, taking integer values with probabilities, respectively (binomial coefficient; p parameter of the B. r., called the probability of a positive outcome, taking the values ... Mathematical Encyclopedia
Probability distribution of the number of occurrences of a certain event during repeated independent trials. If during each trial the probability of an event occurring is equal to p, with 0 ≤ p ≤ 1, then the number μ of occurrences of this event for n independent... ... Big Soviet encyclopedia
- (Bernoulli distribution), the probability distribution of the number of occurrences of a certain event during repeated independent trials, if the probability of the occurrence of this event in each trial is equal to p (0<или = p < или = 1). Именно, число м появлений … Natural science. encyclopedic Dictionary
Binomial probability distribution- (binomial distribution) A distribution that is observed in cases where the outcome of each independent experiment (statistical observation) takes one of two possible values: victory or defeat, inclusion or exclusion, plus or ... Economic and mathematical dictionary
binomial probability distribution- A distribution that is observed in cases where the outcome of each independent experiment (statistical observation) takes one of two possible values: victory or defeat, inclusion or exclusion, plus or minus, 0 or 1. That is... ... Technical Translator's Guide
Books
- Probability theory and mathematical statistics in problems. More than 360 problems and exercises, D. A. Borzykh. The proposed manual contains tasks of varying levels of complexity. However, the main emphasis is on tasks of medium complexity. This is done intentionally to encourage students to...
- Probability theory and mathematical statistics in problems More than 360 problems and exercises, D. Borzykh. The proposed manual contains problems of varying levels of complexity. However, the main emphasis is on tasks of medium complexity. This is done intentionally to encourage students to...
 Russian students won the ICPC World Programming Championship
Russian students won the ICPC World Programming Championship “Denisovan man” “inherited” most of all in the genome of Asians
“Denisovan man” “inherited” most of all in the genome of Asians Action to intimidate checkpoints in Chelyabinsk What is the Concept of Public Safety
Action to intimidate checkpoints in Chelyabinsk What is the Concept of Public Safety