One gene one enzyme modern interpretation. The theory of one gene - one enzyme
4.2.1. The “one gene, one enzyme” hypothesis
First research. After Garrod pointed out in 1902 that the genetic defect in alkaptonuria was associated with the body's inability to break down homogentisic acid, it was important to elucidate the specific mechanism underlying this disorder. Since it was already known at that time that metabolic reactions are catalyzed by enzymes, it could be assumed that it was the disruption of some enzyme that led to alkaptonuria. Such a hypothesis was discussed by Driesch (in 1896). It was also expressed by Haldane (1920, see) and Garrod (1923). Important stages The development of biochemical genetics began with the work of Küchn and Butenandt on the study of eye color in the mill moth Ephestia kuhniella and similar studies by Beadle and Ephrussi on Drosophila(1936). In these pioneering works, insect mutants previously studied by genetic methods were selected to elucidate the mechanisms of gene action. However, this approach did not lead to success. The problem turned out to be too complex, and to solve it it was necessary:
1) select a simple model organism convenient for experimental study;
2) look for the genetic basis of biochemical traits, rather than the biochemical basis of genetically determined traits. Both conditions were met in the work of Beadle and Tatum in 1941 (see also Beadle, 1945).
Beadle and Tatum's model. The article by these researchers began like this:
“From the point of view of physiological genetics, the development and functioning of an organism can be reduced to a complex system of chemical reactions that are somehow controlled by genes. It is quite logical to assume that these genes... either act as enzymes themselves or determine their specificity. It is known that geneticist-physiologists usually try to investigate the physiological and biochemical basis of already known hereditary traits. This approach made it possible to establish that many bio chemical reactions controlled by specific genes. Such studies have shown that enzymes and genes have specificity of the same order. However, the capabilities of this approach are limited. The most serious limitation is that in this case, researchers come to the attention of hereditary traits that do not have a lethal effect and, therefore, are associated with reactions that are not very significant for the life of the organism. The second difficulty... is that the traditional approach to the problem involves the use of externally manifested signs. Many of them are morphological variations based on biochemical reaction systems so complex that their analysis is unusually difficult.
Similar considerations led us to the following conclusion. The study of the general problem of genetic control of biochemical reactions that determine development and metabolism should be carried out using procedure opposite to the generally accepted one: Instead of trying to find out the chemical basis of known hereditary traits, it is necessary to establish whether and how genes control known biochemical reactions. Neurospora, which belongs to the ascomycetes, has properties that make it possible to implement such an approach and at the same time serves as a convenient object for genetic research. That is why our program was built on the use of this particular organism. We assumed that X-ray exposure causes mutations in genes that control certain chemical reactions. Suppose that in order to survive in a given environment, an organism must carry out some kind of chemical reaction, then a mutant lacking such an ability will be unviable under these conditions. However, it can be maintained and studied if grown in a medium to which the vital product of a genetically blocked reaction has been added.”
4 Action of genes 9
Rice. 4.1. Scheme of an experiment to detect biochemical mutants of Neurospora In a complete medium, mutations induced by X-rays or ultraviolet radiation do not disrupt the growth of the fungus. However, the mutant does not grow on minimal medium. When vitamins are added to a minimal medium, the ability to grow is restored. When amino acids are added, there is no growth. Based on these data, it can be assumed that the mutation has occurred in a gene that controls vitamin metabolism. The next step is to identify a vitamin that can restore normal function. A genetic block is found among the reactions of vitamin biosynthesis .Next, Beadle and Tatum describe the experimental design (Fig. 4.1). The complete medium contained agar, inorganic salts, malt extract, yeast extract and glucose. Minimal medium contained only agar, salts, biotin, and a carbon source. The mutants that grew in complete medium and did not grow in minimal medium were studied in most detail. To identify the compound whose synthesis was impaired in each of the mutants, individual components of the complete medium were added to minimal agar.
In this way, strains were isolated that were unable to synthesize certain growth factors: pyridoxine, thiamine and para-aminobenzoic acid. These defects have been shown to be caused by mutations at specific loci. The work laid the foundation for numerous studies on Neurospora, bacteria and yeast, in which the correspondence of “genetic blocks” responsible for individual metabolic stages and specific enzyme disorders was established. This approach has quickly become a tool that allows researchers to uncover metabolic pathways.
The “one gene - one enzyme” hypothesis has received strong experimental confirmation. As the work of subsequent decades showed, it turned out to be surprisingly fruitful. Analysis of defective enzymes and their normal variants soon made it possible to identify a class of genetic disorders that led to changes in the function of the enzyme, although the protein itself was still detectable and retained its immunological properties. In other cases, the temperature optimum for enzyme activity changed. Some variants could be explained by a mutation affecting a general regulatory mechanism and, as a result, changing the activity of an entire group of enzymes. Similar studies led to the creation of the concept of regulation of gene activity in bacteria, which included the concept of an operon.
10 4. Action of genes
The first examples of enzymatic disorders in humans. The first hereditary human disease for which an enzymatic disorder could be demonstrated was methemoglobinemia with a recessive mode of inheritance (Gibson and Harrison, 1947; Gibson, 1948) (25080). In this case, the damaged enzyme is NADH - dependent methemoglobin reductase. The first attempt to systematically study a group of human diseases associated with metabolic defects was made in 1951. In a study of glycogen storage disease, the Coreys showed that in eight out of ten cases of the pathological condition that was diagnosed as Gierke's disease (23220), the liver glycogen structure was normal, and in two cases it was clearly abnormal. It was also obvious that liver glycogen, accumulating in excess, could not be directly converted into sugar, since patients tended to hypoglycemia. Many enzymes are needed to break down glycogen to form glucose in the liver. Two of them, amylo-1,6-glucosidase and glucose 6-phosphatase, were selected for study as possible defective elements of the enzyme system. The release of phosphate from glucose-6phosphate was measured in liver homogenates at different pH values. The results are presented in Fig. 4.2. In normal liver, high activity was found with an optimum at pH 6-7. Severe liver dysfunction in cirrhosis correlated with a slight decrease in activity. On the other hand, in the case of Gierke's disease with a fatal outcome, enzyme activity could not be detected at all; the same result was obtained when examining a second similar patient. Two patients with less severe symptoms had a significant decrease in activity.
It was concluded that in these cases of fatal Gierke's disease there was a defect in glucose-6-phosphatase. However, in most milder cases, the activity of this enzyme was no lower than in liver cirrhosis, and in only two patients it was slightly lower (Fig. 4.2).
According to the Coreys, the abnormal accumulation of glycogen in muscle tissue cannot be associated with a lack of glucose-6-phosphatase, since this enzyme is absent in muscles and is normal. They suggested impaired amylo-1,6-glucosidase activity as a possible explanation for muscle glycogenosis. This prediction was soon confirmed: Forbes discovered such a defect in one of the clinically significant cases of glycogen storage disease involving the cardiac and skeletal muscles. Now we
4. Action of genes 11
A large number of enzymatic defects are known in glycogen storage disease.
Although the various forms of this disease differ somewhat in the degree of manifestation, clinically they have much in common. With one exception, they are all inherited in an autosomal recessive manner. If enzymatic defects had not been discovered, the pathology of glycogen storage would be considered as one disease with characteristic intrafamilial correlations in severity, symptomatic details and timing of death. Thus, we have before us an example where genetic heterogeneity, which could only be assumed based on the study of the phenotype (section 3.3.5), was confirmed by analysis at the biochemical level: research enzymatic activity allowed the identification of specific genes.
In subsequent years, the pace of research in the field of enzymatic defects increased, and for the 588 identified recessive autosomal genes that McKusick describes in the sixth edition of his book Mendelian Inheritance in Man (1983), specific enzymatic defects were found in more than 170 cases. Our progress in this field is directly related to the development of concepts and methods of molecular genetics.
Some stages of studying enzymatic disorders in humans. We present only the most important milestones of this ongoing process: 1934 Fölling discovered phenylketonuria
1941 Beadle and Tatum formulated the “one gene, one enzyme” hypothesis 1948 Gibson described the first case of an enzymatic disorder in a human disease (recessive methemoglobinemia)
1952 The Coreys discovered glucose-6-phosphatase deficiency in Gierke's disease
1953 Jervis demonstrated the absence of phenylalanine hydroxylase in phenylketonuria. Bickel reported the first attempt to mitigate an enzymatic disorder using a low phenylalanine diet
1955 Smithies developed starch gel electrophoresis technique
1956 Carson et al discovered a defect in glucose-6-phosphate dehydrogenase (G6PD) in a case of induced hemolytic anemia
1957 Kalkar et al. described enzymatic deficiency in galactosemia, showing that humans and bacteria have identical defects in enzymatic activity
1961 Krut and Weinberg demonstrated an enzyme defect in galactosemia in vitro in cultured fibroblasts
1967 Seegmiller et al discovered a hypoxanthine-guanine phosphoribosyltransferase (HPRT) defect in Lesch-Nyhan syndrome
1968 Cleaver described a disorder of excision repair in xeroderma pigmentosum
1970 Neufeld identified enzymatic defects in mucopolysaccharidoses, which made it possible to identify pathways for the breakdown of mucopolysaccharides
1974 Brown and Goldstein proved that genetically determined overproduction of hydroxymethylglutarylCoA reductase in familial hypercholesterolemia is due to a defect in the membrane-localized low-density lipoprotein receptor, which modulates the activity of this enzyme (HMG)
1977 Sly et al demonstrated that mannose-6-phosphate (as a component of lysosomal enzymes) is recognized by fibroblast receptors. A genetic processing defect prevents the binding of lysosomal enzymes, as a result of which their release into the cytoplasm and subsequent secretion into the plasma is impaired (I-cell disease)
12 4. Action of genes
1980 In pseudohypoparathyroidism, a defect in the protein that ensures the coupling of the receptor and cyclase is discovered.
Many chemical reactions occur in every living cell. Enzymes are proteins with special and extremely important functions. They are called biocatalysts. The main thing in the body is to accelerate biochemical reactions. The initial reagents, the interaction of which is catalyzed by these molecules, are called substrates, and the final compounds are called products.
In nature, enzyme proteins work only in living systems. But in modern biotechnology, clinical diagnostics, pharmaceuticals and medicine, purified enzymes or their complexes are used, as well as additional components necessary for the operation of the system and data visualization for the researcher.
Biological significance and properties of enzymes
Without these molecules, a living organism would not be able to function. All vital processes work smoothly thanks to enzymes. The main function of enzyme proteins in the body is to regulate metabolism. Without them, normal metabolism is impossible. Regulation of the activity of molecules occurs under the influence of activators (inducers) or inhibitors. Control operates on different levels protein synthesis. It also “works” on a ready-made molecule.
The main properties of enzyme proteins are specificity to a particular substrate. And, accordingly, the ability to catalyze only one or, less often, a series of reactions. Usually such processes are reversible. One enzyme is responsible for both functions. But that is not all.

The role of enzyme proteins is essential. Without them, biochemical reactions do not occur. Due to the action of enzymes, it becomes possible for reagents to overcome the activation barrier without significant energy expenditure. It is not possible for the body to heat the temperature above 100 °C or use aggressive components such as chemical laboratory. The enzyme protein binds to the substrate. In the bound state, modification occurs with the subsequent release of the latter. This is exactly how all catalysts used in chemical synthesis operate.
What are the levels of organization of a protein-enzyme molecule?
Typically these molecules have a tertiary (globule) or quaternary (several connected globules) protein structure. They are first synthesized in linear form. And then they collapse into the required structure. To ensure activity, a biocatalyst needs a certain structure.

Enzymes, like other proteins, are destroyed by heat, extreme pH values, and aggressive chemical compounds.
Additional properties of enzymes
Among them are the following features of the components:
- Stereospecificity - the formation of only one product.
- Regioselectivity - gap chemical bond or modification of the group in only one position.
- Chemoselectivity - catalysis of only one reaction.
Features of work
Level varies. But any enzyme is always active against a specific substrate or group of compounds that are similar in structure. Non-protein catalysts do not have this property. Specificity is measured by the binding constant (mol/L), which can reach 10−10 mol/L. The work of the active enzyme is rapid. One molecule catalyzes thousands to millions of operations per second. The degree of acceleration of biochemical reactions is significantly (1000-100000 times) higher than that of conventional catalysts.
The action of enzymes is based on several mechanisms. The simplest interaction occurs with one substrate molecule followed by the formation of a product. Most enzymes are capable of binding 2-3 different molecules that enter into a reaction. For example, the transfer of a group or atom from one compound to another or double substitution using the “ping-pong” principle. In these reactions, one substrate is usually combined, and the second is linked through a functional group to the enzyme.
The study takes place using methods:
- Definitions of intermediate and final products.
- Studying the geometry of the structure and functional groups associated with the substrate and providing high
- Mutations of enzyme genes and determination of changes in its synthesis and activity.

Active and binding site
The substrate molecule is much smaller in size than the enzyme protein. Therefore, binding occurs due to a small number of functional groups of the biocatalyst. They form an active center consisting of a specific set of amino acids. The structure contains a prosthetic group of non-protein nature, which can also be part of the active center.
A separate group of enzymes should be distinguished. Their molecule contains a coenzyme that constantly binds to the molecule and is released from it. A fully formed enzyme protein is called a holoenzyme, and when the cofactor is removed, it is called an apoenzyme. Vitamins, metals, derivatives of nitrogenous bases (NAD - nicotinamide adenine dinucleotide, FAD - flavin adenine dinucleotide, FMN - flavin mononucleotide) often act as coenzymes.

The binding site provides substrate affinity specificity. Due to it, a stable substrate-enzyme complex is formed. The structure of the globule is constructed in such a way as to have a niche (slit or depression) of a certain size on the surface, ensuring the binding of the substrate. This zone is usually located near the active center. Individual enzymes have sites for binding to cofactors or metal ions.
Conclusion
Enzyme protein plays an important role in the body. Such substances catalyze chemical reactions and are responsible for the metabolic process - metabolism. In any living cell, hundreds of biochemical processes constantly occur, including reduction reactions, cleavage and synthesis of compounds. Substances are constantly oxidized with a large release of energy. It, in turn, is spent on the formation of carbohydrates, proteins, fats and their complexes. Decomposition products are structural elements for the synthesis of necessary organic compounds.
» , » One gene, one enzyme
One gene, one enzyme
92
Publication date: July 24, 2018
The one gene, one enzyme hypothesis is the idea, put forward in the early 1940s, that each gene controls the synthesis or activity of one enzyme. The concept, which combines the fields of genetics and biochemistry, was proposed by the American geneticist George Wells Beadle and the American biochemist Edward L. Tatum, who conducted research on Neurospora crassa. Their experiments involved first imaging the form to mutation-inducing X-rays and then culturing it in minimal growth medium that contained only the essential nutrients needed for the wild-type strain to survive. They discovered that the mutant mold strains required the addition of certain amino acids to grow. Using this information, the researchers were able to link mutations in certain genes to disruption of specific enzymes in metabolic pathways that typically produced the missing amino acids. It is now known that not all genes encode an enzyme and that some enzymes consist of several short polypeptides encoded by two or more genes.
Discoveries of the exon-intron organization of eukaryotic genes and the possibility of alternative splicing showed that the same nucleotide sequence of the primary transcript can ensure the synthesis of several polypeptide chains with different functions or their modified analogues. For example, yeast mitochondria contain a box (or cob) gene that encodes the respiratory enzyme cytochrome b. It can exist in two forms: The “long” gene, consisting of 6400 bp, has 6 exons with a total length of 1155 bp. and 5 introns. The short form of the gene consists of 3300 bp. and has 2 introns. It is actually a “long” gene lacking the first three introns. Both forms of the gene are equally well expressed.
After removing the first intron of the “long” box gene, based on the combined nucleotide sequence of the first two exons and part of the nucleotides of the second intron, a matrix is formed for an independent protein - RNA maturase (Fig. 3.43). The function of RNA maturase is to ensure the next step of splicing - the removal of the second intron from the primary transcript and ultimately the formation of a template for cytochrome b.
Another example is a change in the splicing pattern of the primary transcript encoding the structure of antibody molecules in lymphocytes. The membrane form of antibodies has a long “tail” of amino acids at the C-terminus, which ensures the fixation of the protein on the membrane. The secreted form of antibodies does not have such a tail, which is explained by the removal of the nucleotides encoding this region from the primary transcript during splicing.
In viruses and bacteria, a situation has been described where one gene can simultaneously be part of another gene, or a certain DNA nucleotide sequence can be part of two different overlapping genes. For example, the physical map of the genome of phage FX174 (Fig. 3.44) shows that the sequence of gene B is located inside gene A, and gene E is part of the sequence of gene D. This feature of the organization of the phage genome was able to explain the existing discrepancy between its relatively small size (it consists of 5386 nucleotides) and the number of amino acid residues in all synthesized proteins, which exceeds what is theoretically permissible for a given genome capacity. The possibility of assembling different peptide chains on mRNA synthesized from overlapping genes (A and B or E and D) is ensured by the presence of ribosome binding sites within this mRNA. This allows translation of another peptide to begin from a new starting point.
The nucleotide sequence of gene B is simultaneously part of gene A, and gene E is part of gene D
Overlapping genes, translated both with a frameshift and in the same reading frame, were also found in the λ phage genome. It is also assumed that it is possible to transcribe two different mRNAs from both complementary strands of one DNA section. This requires the presence of promoter regions that determine the movement of RNA polymerase in different directions along the DNA molecule.
The described situations, indicating the permissibility of reading different information from the same DNA sequence, suggest that overlapping genes are a fairly common element of the organization of the genome of viruses and, possibly, prokaryotes. In eukaryotes, gene discontinuity also allows for the synthesis of a variety of peptides from the same DNA sequence.
With all this in mind, it is necessary to amend the definition of the gene. Obviously, we can no longer talk about a gene as a continuous sequence of DNA that uniquely encodes a specific protein. Apparently, at present, the formula “One gene - one polypeptide” should still be considered the most acceptable, although some authors propose to change it: “One polypeptide - one gene”. In any case, the term gene must be understood as a functional unit of hereditary material, which by its chemical nature is a polynucleotide and determines the possibility of synthesizing a polypeptide chain, tRNA or rRNA.
One gene, one enzyme.
In 1940, J. Beadle and Edward Tatum used a new approach to study how genes provide metabolism in a more convenient research subject - the microscopic fungus Neurospora crassa. They obtained mutations in which; there was no activity of one or another metabolic enzyme. And this led to the fact that the mutant fungus was not able to synthesize a certain metabolite on its own (for example, the amino acid leucine) and could only live when leucine was added to the nutrient medium. The theory of “one gene, one enzyme” formulated by J. Beadle and E. Tatum quickly gained wide recognition among geneticists, and they themselves were awarded the Nobel Prize.
Methods. selection of so-called “biochemical mutations” leading to disturbances in the action of enzymes that provide different metabolic pathways turned out to be very fruitful not only for science, but also for practice. First, they led to the emergence of genetics and selection of industrial microorganisms, and then to the microbiological industry, which uses strains of microorganisms that overproduce such strategically important substances as antibiotics, vitamins, amino acids, etc. The principles of selection and genetic engineering of superproducer strains are based on the idea that “one gene codes for one enzyme.” And although this idea is excellent for practice, brings in multimillion-dollar profits and saves millions of lives (antibiotics) - it is not final. One gene is not just one enzyme.
| " |
Genetics- science is by no means young; research in it has been carried out for several centuries, starting with Mendel in 1865 to the present day. The term "gene" for a unit of hereditary characteristic was first proposed by Johannsen in 1911, and was refined in the 1940s by the "one gene, one enzyme" concept proposed by Tatum and Beadle.
This position was determined in experiments on Drosophila flies, but equally applies to humans; Ultimately, the lives of all beings are determined by their DNA. The human DNA molecule is larger than that of all other organisms, and its structure is more complex, but the essence of its functions is the same in all living beings.
Concept " one gene - one enzyme", which arose on the basis of the ideas of Tatum and Beadle, can be formulated as follows:
1. Everything biological processes are under genetic control.
2. All biochemical processes occur in the form of step-by-step reactions.
3. Each biochemical reaction is ultimately under the control of various individual genes.
4. A mutation in a certain gene leads to a change in the cell’s ability to carry out a certain chemical reaction.
Since then, the concept of “one gene - one enzyme” has expanded somewhat, and now sounds like “ one gene - one protein" In addition, recent research suggests that some genes act in concert with others to produce unique proteins, i.e., some genes may encode more than one protein.
Human genome contains about 3 billion nucleotide pairs; it is believed to contain from 50,000 to 100,000. After deciphering the genome, it turned out that there are only about 30,000 genes. The interaction of these genes is much more complex than expected. Genes are encoded in strands of DNA, which combine with certain nuclear proteins to form chromosomes.
Genes- not just DNA segments: they are formed by coding sequences - exons, interspersed with non-coding sequences - nitrons. Exons, as the expressed part of DNA, constitute only a small part of the most important molecule of the organism; most of it is not expressed, is formed by nitrons and is often called “silent” DNA.
Approximate size and structure human genome are presented in the figure below. The functional length of the human chromosome is expressed in centimorganides. Centimorganide (cM) is the distance over which the probability of crossing over during meiosis is 1%. Gene linkage analysis has shown that the length of the human genome is about 3000 cM.
Average chromosome contains approximately 1500 genes encoded in 130 million nucleotide base pairs. The figure below schematically shows the physical and functional sizes of the genome: the first is calculated in nucleotide pairs, and the second in cM. Most of the human genome is represented by “silent” DNA and is not expressed.
On DNA matrix As a result of the transcription process, RNA is synthesized, and then protein. Consequently, the DNA sequence completely determines the sequence of functional proteins of the cell. All proteins are synthesized as follows:
DNA => RNA => protein

The genetic apparatus of humans and other mammals is more complex than that of other living organisms, since sections of some genes in mammals can be combined with parts of others genes, resulting in the synthesis of an entirely new protein or the control of a separate cellular function.
Consequently, in humans it is possible to increase the number of expressed genes without actually increasing the volume of expressed genes. DNA or the absolute number of genes.
Overall, about 70% of all genetic material is not expressed.
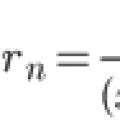 Taylor series expansion Approximate solution of the Cauchy problem for the ordinary
Taylor series expansion Approximate solution of the Cauchy problem for the ordinary What is NOT taught at school What is not taught at school ask
What is NOT taught at school What is not taught at school ask Money Thinking Formula (A
Money Thinking Formula (A